
티스토리 뷰
[논문읽기][STARK]Learning Spatio-Temporal Transformer for Visual Tracking
무엇보다_빛나는_샤트 2022. 2. 16. 23:37안녕하세요
프로그래밍을 배우는 빛나는 샤트입니다.
Abstract, Introduction, 핵심 내용을 제 언어로 정리해 봤습니다.
전체 내용은 추후 업데이트 예정입니다.
일시: 2021.05.29(토)
오늘 읽어볼 논문은 'Learning Spatio-Temporal Transformer for Visual Tracking'입니다.
논문 링크:https://arxiv.org/pdf/2103.17154v1.pdf
Abstract(요약)
우리는 인코더-디코더 트랜스포머를 핵심 구성요소로 사용하는 새로운 추적 아키텍쳐를 소개한다. 디코더가 목표 객체의 공간적 위치를 예측하기 위해 쿼리 임베딩을 배우는 동안 인코더는 목표 객체와 탐색 영역 사이의 글로벌 시공간 특성값을 모델링한다. 우리의 방법은 어떠한 proposal이나 사전 정의된 앵커를 사용하지 않고 직접적 bbox를 예측하는 문제로서 객체 추적을 다뤘다. 인코더-디코더 트랜스포머를 이용해, 객체의 예측은 간단한 FCN을 사용해 객체의 코너를 직접적으로 유추했다. 전체 방법은 end-to-end방식으로 어떠한 전처리 과정(코사인 윈도우, 바운딩 박스 스무딩)을 필요로 하지 않아서 대체로 현존하는 추적 파이프라인들을 단순화할 수 있다. 제안된 추적기는 5가지의 short-term, long-term 벤치마크에서 SOTA를 달성했다.(실시간으로 동작, Siam R-CNN보다 6배 빠름)
1. Introduction
- 기존의 Object Tracking 아키텍쳐는 CNN기반이었지만 CNN 커널은 long-range 이미지의 특성 dependencies을 모델링을 잘하지 못했다.
(왜냐하면 CNN커널은 오직 정해진 공간 또는 시간내에서 local neighborhood에서 처리되었기 때문)
- 트랜스포머는 long-range가 가지고 있는 문제를 잘 해결한다.
- 최근 DEtection TRansformer(DETR)이라는 모델에 영감을 받아 CNN을 넘어설 새로운 Object Tracking 기법(end-to-end방식)을 제안한다.
- 시간과 공간 정보는 객체 추적에 있어 매우 중요한 정보이다.
- 여기에서는 글로벌 종속성 모델링에 대한 우수한 용량을 고려하여 트랜스포머에 의존하여 추적을 위한 공간 및 시간 정보를 통합하여 객체 위치 지정을 위한 차별적 시공간적 특징을 생성한다.
- 정확히는 인코더-디코더 트랜스포머가 기초인 새로운 시공간 아키텍쳐를 비주얼 추적을 위해 만들었다.
- 여기에는 3가지 핵심 요소(인코더, 디코더, 예측 헤드) - an encoder, a decoder, a prediction head
- 인코더: 목표 객체의 초기 입력을 받아서 탬플릿을 업데이트한다. 인코더 내부의 self-attention 모듈은 입력의 특성들과의 관계성을 학습한다. 동영상 시퀀스 전체에 대해 탬플릿 이미지들이 업데이트가 되면 인코더는 타겟의 시공간 정보를 capture한다.
- 디코더: 목표 객체의 공간적 위치를 예측하기 위해 쿼리 임베딩을 학습.
- 예측 헤드: corner-based 예측 헤드는 최근 프레임에서 목표 객체의 bbox를 추정한다. 한편 score head는 다이나믹 템플릿 이미지의 업데이트 제어를 학습한다.
- 많은 실험을 통해 우수한 성능을 확인함
- short-term, long-term 모두 SOTA
- Siam R-CNN보다 3.9%(GOT-10K dataset), 2.3%(LaOST dataset) 우수.
- 우리의 방법은 오직 하나의 네트워크를 이용.(end-to-end fashion)
- 실시간으로 동작 가능. Siam R-CNN보다 6배 빠르다. (Fig.1 참고)

3. Method
- STARK의 아키텍쳐는 Fig.2에서 확인가능.
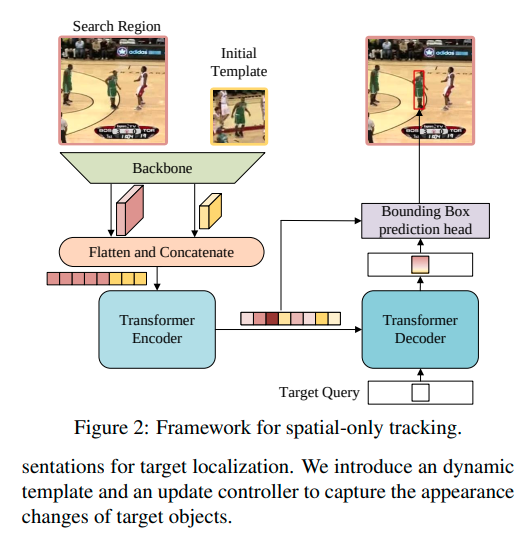
- 여기에는 3가지 주요 요소가 있다: 컨볼루션 백본, 인코더-디코더 트랜스포머, bbox 예측 헤드
3-1. A Simple Baselin Based on Transformer
1) Backbone
- 바닐라 ResNet을 채택.
- 더 정확히 하면, 마지막 stage와 FC layer를 제거하는 것을 제외하면 오리지널 ResNet와 동일하다.
(즉, 여기에서는 마지막 stage와 FC layer를 제거함)
- 입력은 쌍을 이루는 이미지들이다. 초기 타겟 객체의 탬플릿 이미지 & 현재 프레임의 탐색 영역
- Backbone을 모두 통과한 후에는 탬플릿과 탐색 영역 이미지들은 두 개의 feature map으로 매핑된다.
2) Encoder
- Backbone에서 나온 feature map은 Encoder에 들어가기 전에 전처리가 필요.
- 구체적으로 bottleneck layer는 먼저 채널수를 C에서 d로 줄이는 데 사용됨.
- 그리고 feature map은 flatten과 concat를 거친다.(시간 차원에 맞게)
(flatten + concat: 길이(H_z/s * W_z/s + H_x/s * W_x/s), d차원)
- 총 N개의 encoder layer 각각은 (순전파 진행 시) multi-head self-attention 모듈로 이루어져 있음.
- 오리지널 트랜스포머의 영구적 불변성 때문에 sinusoidal(정현파; sin파) 위치적 임베딩을 추가했다.
- encoder는 모든 요소의 특성을 잡아낼 수 있고 오리지널 특성을 강화한다. --> 이 때문에 모델이 객체 위치를 구분하는 차별적 위치 특성을 잘 학습 가능
3) Decoder
- decoder의 입력: encoder에서 나온 target query와 강화된 특성 시퀀스
- DETR이 100개의 객체 query를 채택한 반면, 우리는 단지 하나의 단일 query를 decoder에 집어 넣어 목표 객체에 대한 bbox를 예측할 수 있다.
- 게다가 오직 하나의 예측을 하기 때문에 헝가리안 알고리즘을 제거할 수 있다.(DETR에서는 사용함)
- M개의 layer를 쌓는다.(stack) 여기에는 self-attention, encoder-decoder-attention, 순전파(feed-forward network)가 포함.
- encoder-decoder-attention 모듈: target query는 템플릿 내의 모든 위치에 대해 attend할 수 있고, 영역 특성을 탐색할 수 있다.
그래서 마지막 bbox 예측의 강경한 대표성(robust repersentation) 배운다.
4) Head
- 우리는 박스 코너의 확률 분포를 통과하는 새로운 예측 head를 설계.
- Fig.3 설명
1) encoder의 출력으로부터 나온 탐색 영역 특성을 첫 번째로 받는다.
2) 그리고 나서 decoder에서 나온 출력 임베딩과 탐색 영역 특성의 유사성을 연산한다.
3) 유사성 점수는 탐색 영역 특성과 약화된 덜 구별적인 것을 element-wisely 방식으로 곱한다. (강화된 중요한 영역으로 변화하기 위해)
4) 새로운 특성 시퀀스는 feature map으로 reshape되며 간단한 FCN에 들어가게 된다.
5) FCN은 L개의 Conv-BN-ReLU layer들을 쌓아둠.(stack) 그리고 객체의 bbox의 좌측 상단, 우측 하단의 좌표 가능성 값을 출력.
6) 최종적으로 예측된 박스의 좌표들은 공식1에 의해 계산되어 얻어진다.
- DETR과 비교해보면 우리의 방법은 명백히 좌표 추정의 불확실성을 모델링해서 객체 추적을 위한 더 강력하고 정확한 예측을 실시한다.
5) 학습과 추론(Training and Inference)
- 우리의 베이스라인 추적기는 end-to-end방식으로 학습되었으며, 이는 L1 loss와 DETR 내부에서 생성된 IoU loss의 결합에 의해서 이루어짐.
- DETR과 다른 점은 classification loss와 헝가리안 알고리즘을 사용하지 않았다. 그래서 학습 과정을 단순화할 수 있었었음.
- 추론하는 동안 백본에서부터 나온 탬플릿 이미지와 그 특성은 첫 번째 프레임에 의해 초기화 되었고 이후 프레임 내에서 고정되었다.
- 추적하는 동안 모든 프레임에 대해 네트워크는 최근 프레임을 입력으로부터 나온 탐색 영역을 입력으로 받았고 예측 박스를 최종 결과로 반환했다.
(어떠한 후처리;코사인 윈도우 또는 바운딩 박스 스무딩 를 사용하지 않았음)
3-2. Spatio-Temporal Transformer Tracking
- 시간 흐름에 따라 추적 객체의 외관이 변경된 이후부터는 타겟의 최근 상태를 알아내는 것은 추적에 있어 중요함.
- 여기에서는 이전에 소개한 베이스라인을 기반으로 시간 정보와 공간 정보를 동시에 활용하는 방법 보여준다.
- 세 가지 중요한 차이점들이 생성됨(네트워크 입력, 잔여 점수 헤드(extra score head), training & inference 전략)
2.Related Work는 굳이 넣지 않았습니다.
--> NLP task에서만 봤던 transformer모델을 CV task인 Object Tracking에 활용한 점이 인상적임.
--> 시간, 공간 정보를 활용해 적절한 위치를 추적하는 점이 흥미로움
*아직 논문 읽기 초보가 작성했기때문에 오류가 많이 있을 수 있습니다.
내용에 오류가 있으면 피드백 언제나 환영입니다.😊
'ML DL' 카테고리의 다른 글
| [지시딥] SGD와 BGD 그리고 학습 (0) | 2022.02.16 |
|---|---|
| [지시딥] chapter 6 .학습 관련 기술들(p189~208) (0) | 2022.02.16 |
| [논문읽기][SSD]Single Shot MultiBox Detector (0) | 2022.02.16 |
| [논문읽기][EfficientNet]Rethinking Model Scaling for Convolutional Neural Networks (0) | 2022.02.16 |
| [논문읽기][DenseNet]Densely Connected Convolutional Networks 논문 읽기 (0) | 2022.02.16 |
- Total
- Today
- Yesterday
- 도전
- 광주인공지능사관학교
- Python
- SLAM강의
- IT
- 자율주행기술
- 배달로봇
- 광주AI
- Slam
- 서빙로봇
- 멋쟁이사자처럼
- 실내자율주행
- 인공지능 교육
- 광주
- ros
- SLAM공부
- 양정연SLAM
- 모두의연구소
- AIFFEL
- 자율주행로봇
- 대전 인공지능
- AIFFEL후기
- 모두의 연구소
- 아이펠
- 멘탈관리
- AIFFEL교육
- 인공지능
- AIFFEL인공지능과정
- 인공지능교육
- 해커톤
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |