
티스토리 뷰
2021. 10. 5. 23:54
안녕하세요
프로그래밍을 배우는 빛나는 샤트입니다.
SLAM 강의 20강. Bayesian Classifier
*이 포스팅은 목원대학교 양정연 교수님의 SLAM강의 유튜브 영상을 보고 제작되었음을 밝힙니다.
출처: 20강. Bayesian Classifier
20강. Bayesian Classifier
🎉강의요약
1. Likelihood, Posterior 두 가지 기법을 비교하면 비슷해보이지만 자세히 살펴보면 다르다.
2. 특히 에러에서 두드러지는데 Likelihood의 경우 prior의 값이 같다면 에러가 더욱 커진다.
3. prior이 다르다고 해도 베이지안 기법이 훨씬 더 유용하다.
4. 다른 분류기보다 좋은 성능을 가지고 있으므로 선행해서 에러를 살펴볼 필요가 있다.
5. 또한 문제 해결 시 threshold를 이용하는 것은 공학적이지 않다.
6. 인식기 설계 시 문제를 명확히 정의해야 한다.

<What is the difference between likelihood and Posterior probability?>
likelihood 기법: 키 큰 사람 평균이 181, 작은 사람 평균이 165이니까 175는 큰 확률이 더 크지 않을까?
Posterior 기법: 키가 175일 때 키가 큰 확률, 작은 확률을 구해서 비교.
> Posterior은 선택이 아니라 필수적이다.

<Exampel: Test4.m>
x=175일때 likelihood와 posterior을 각각 구한 결과이다.
둘 다 키가 크다고 판별한다 > 하지만 꼼꼼하게 봐야한다.

<Theoretical Interest>
error를 구해본다.
모든 P(e) = P(e|x)P(x)
분류기는 w1,w2중에서 큰 것이고 (argmax)
에러는 w1,w2 중에서 작은 것 (argmin)

<Bayesian Error is>
크기가 굉장히 작다.
많은 경우에 베이지안 분류기는 잘 작동. (대부분의 신경망보다 좋다)
베이지안 분류기를 이용해 선행으로 에러를 검출하는 것이 좋다.
likelihood보다 훨씬 더 작다.
질문: 왜 딥러닝은 좋은가?
specific한 모델에 general한 것도 많이 집어넣게 되면 학습 능력이 올라간다.
얼굴 인식기에 얼굴이 아닌 것도 학습하면 성능이 올라간다.
데이터를 많이 주입하고 히든 레이어의 역할이 크다. feature를 특정하지 않고 알아서 학습한다. 히든 레이어를 통과할 때마다 계속 맞는 것을 종합한다.
w1뿐만 아니라 w2도 찾기 때문에 general한 솔루션을 모두 고려하기 때문에 좋다.

<Example Test 5, Plot everything>
좌측은 P(x)
우측은 분류기. 170가량에서 키가 크다고 바뀜.
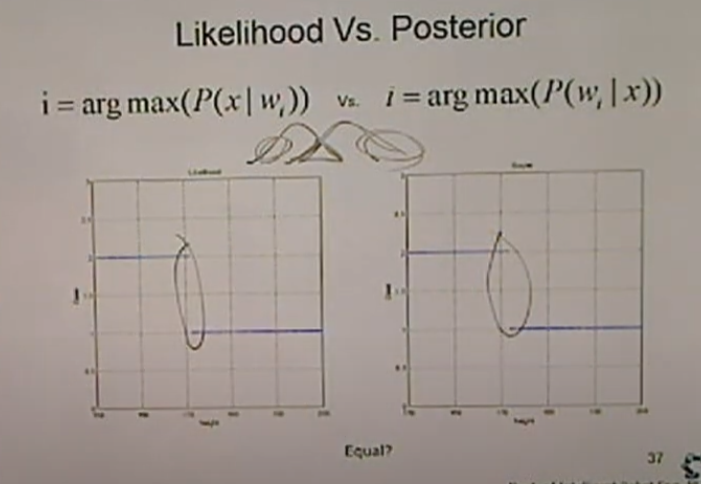
<LIkelihood VS Posterior>
비슷해보이지만...겹치는 부분을 잘 봐야한다.

<Overlapped Area>
LH: 171도 작다고 판단.
P: 172부터 크다고 판단.

<The Most Important Factor of Classifier. -> Minimize Error on Overlapped data>
아래는 prior이 같을 경우이다. 분류기 성능이 동일.
에러를 구해보면, 파란색(LH), 빨간색(베이지안)
베이지안이 훨씬 작은것을 알 수 있다.

<Problem of LIkelihood. When p(w1) ≠ p(w2)>
아래 예시처럼 두 값이 너무 차이가 크면 LH 에러값이 너무 크다.

<Example of Bayesian Classifier: Sensor for Something>
스크린 도어의 센서값을 설계할 때 베이지안 분류기를 적용해야 한다.

<Who will choose threshold?>
1. threshold는 공학적인 방법이 아니다. > 연속적인 공간이 아닐 때는 사용 가능
2. Likelihood: 데이터를 모아서 했지만..그래도 부족함
3. Bayesian: 센서의 설계는 문제없다고 봐도 된다.

<Specification of Bayesian Classification>
매개변수 기반의 방법이다. 평균, 표준편차를 이용. 데이터의 패턴을 가우시안으로 표현.
샘플이 가우시안 형태를 보여줘야 한다.
정규분포인지 확인하는 과정이 필요.

<Classfication and Features>
x는 사건 이벤트 등이 될 수 있다.
또한 좋은 feature를 찾아야 한다. 예시) 공과 공이 아닌 것 둘 다 입력해야 함.
>> General한 요소도 추가해야함
인식기를 만들 때는 각각의 이벤트를 명확하게 정의해야함!
피드백은 언제나 환영합니다.😊
틀린 부분 있다면 지적해주시고 도움이 되었다면 댓글과 공감 눌러주세요
'SLAM' 카테고리의 다른 글
| [SLAM] 양정연 교수 SLAM 강의 22강. Non Parametric Method (0) | 2022.02.21 |
|---|---|
| [SLAM] 양정연 교수 SLAM 강의 21강. Probabilistic Approaches (0) | 2022.02.21 |
| [SLAM] 양정연 교수 SLAM 강의 19강. Bayesian Probabilisty (0) | 2022.02.21 |
| [SLAM] 양정연 교수 SLAM 강의 18-2강. Normal Distribution in 2 Dim. Space (0) | 2022.02.21 |
| [SLAM] 양정연 교수 SLAM 강의 18강. Normal Distribution (0) | 2022.02.21 |
- Total
- Today
- Yesterday
- AIFFEL교육
- AIFFEL인공지능과정
- 멋쟁이사자처럼
- 아이펠
- 멘탈관리
- ros
- IT
- SLAM강의
- 모두의연구소
- 광주인공지능사관학교
- 해커톤
- 양정연SLAM
- 실내자율주행
- Slam
- AIFFEL
- 광주
- 모두의 연구소
- 배달로봇
- 도전
- SLAM공부
- 인공지능교육
- 광주AI
- 인공지능 교육
- 서빙로봇
- Python
- 자율주행로봇
- 자율주행기술
- 인공지능
- AIFFEL후기
- 대전 인공지능
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |