
티스토리 뷰
sequence to sequence(시계열에서 시계열로): 한 시계열 데이터에서 다른 시계열 데이터로 변환
- 기계 번역, 챗봇, 메일의 자동 답신 등 다양하게 응용 가능
2. RNN을 사용한 문장 생성 순서

- "you say goodbye and I say hello." 를 학습한 모델
- 여기에 "I"를 입력하면? 아래와 같이 다음 출현할 단어의 확률분포 출력

다음 단어를 출력하기 위한 방법 2가지
1) 확률이 가장 높은 단어 선택 (결정적)
>> 위에서는 "say"가 가장 높으므로 "say"가 출력.
2) 확률에 기반에 출력 (확률적) - 책에서는 이 방법 선택
>> 전체 확률분포를 이용해 샘플링한다. (물론 "say"의 확률이 가장 높으므로 "say"가 나올 확률이 높지만 다른 단어도샘플링될 수 있다!)

이와 같은 작업을 계속 반복하면 된다. (<eos>와 같이 문장 종결을 의미하는 단어가 나올때까지)

>> 여기서 주목할 점! 이렇게 생성한 문장은 훈련 데이터에 존재하지 않는다. (새로운 문장 생성!)
왜냐하면, 언어 모델은 훈련 데이터를 암기한 것이 아니라 훈련 데이터에서 사용된 단어의 정렬 패턴을 학습
3. RNN을 이용한 문장 생성 code 보기
3-1. 문장 생성 구현 code (1) - 모델 생성
import sys
sys.path.append('..')
import numpy as np
from common.functions import softmax
from ch06.rnnlm import Rnnlm
from ch06.better_rnnlm import BetterRnnlm
class RnnlmGen(Rnnlm):
def generate(self, start_id, skip_ids=None, sample_size=100):
word_ids = [start_id]
x = start_id
while len(word_ids) < sample_size:
x = np.array(x).reshape(1, 1)
score = self.predict(x)
p = softmax(score.flatten())
sampled = np.random.choice(len(p), size=1, p=p)
if (skip_ids is None) or (sampled not in skip_ids):
x = sampled
word_ids.append(int(x))
return word_ids1) generate의 인자
- start_id: 최초로 주는 단어의 ID
- sample_size: 샘플링하는 단어의 수
- skip_id: 단어 ID의 리스트. 이 리스트에 속하는 단어ID는 샘플링되지 않게 한다. (PTB데이터 셋에 있는 <unk>나 N 등 전처리 된 단어를 샘플링하지 않게 하는 용도로 사용)
2) 동작 Process
(1) self.predict(x)를 통해 정규화 되기 전 각 단어의 점수 호출
(2) p = softmax(socre.flatten())을 통해 이 점수들을 소프트맥스 함수를 통해 정규화 >> 목표로 하는 확률분포 얻는다.
(3) sampled = np.random.choice(len(p), size=1, p=p)를 통해 다음 단어 샘플링(랜덤으로 초이스)
(4) 샘플링 금지 단어가 없거나 샘플링한 단어가 샘플링 금지 단어 리스트 안에 없다면 -> word_ids에 추가
(5) word_ids 반환
3-1. 문장 생성 구현 code (2) - 문장 생성
import sys
sys.path.append('..')
from rnnlm_gen import RnnlmGen
from dataset import ptb
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
corpus_size = len(corpus)
model = RnnlmGen()
# model.load_params('../ch06/Rnnlm.pkl')
# start 문자와 skip 문자 설정
start_word = 'you'
start_id = word_to_id[start_word]
skip_words = ['N', '<unk>', '$']
skip_ids = [word_to_id[w] for w in skip_words]
# 문장 생성
word_ids = model.generate(start_id, skip_ids)
txt = ' '.join([id_to_word[i] for i in word_ids])
txt = txt.replace(' <eos>', '.\n')
print(txt)1) 말뭉치 불러오기
2) 모델 불러오기
3) 시작 단어 설정 = "you"
4) 시작 단어를 단어 ID로 변환
5) skip_words설정(샘플링하면 안 되는 단어 리스트)
6) skip_words를 단어 ID로 변환
7) 모델 동작 (단어ID로 이루어진 리스트로 반환)
8) txt변수에 .join()메소드를 이용해 띄어쓰기 구분자를 활용해 단어 ID(숫자) -> 단어(문자열)로 변환
9) 문장 끝에 있는 구분 단어인 ' '를 줄바꿈을 의미하는 '.\n'로 변환

여기서 잠깐! .join() 간단한 예시
' '.join('you', 'say', 'goodbye')
# 'you say goodbye'
문장 생성이 엉터리인 이유?
- 모델의 가중치 초깃값으로 무작위한 값을 사용했기 때문.
학습을 끝낸 가중치를 이용해 문장 생성실시
- 위 코드 중 주석 처리된 model.load_params('../ch06/Rnnlm.pkl') 해제 후 실시

4. 더 좋은 문장 만들어보기
이전 장에서 더 좋은 언어 모델을 BetterRnnlm 클래스로 구현함!
구현 방식은 클래스 상속을 이용한 윗 방법과 동일하므로 코드는 생략.
결과는 아래와 같다. (첫 문자는 'you')

이전과 비교해본다면 문장구조가 더 자연스러워졌음을 알 수 있다!
하지만 좀 더 발전시키고 싶다면 한층 더 큰 말뭉치를 사용한다면 더 자연스러운 문장을 생성할 것!
5. seq2seq
- 2개의 RNN을 이용
- Encoder-Decoder 모델 (2개의 모듈, Encoder, Decoder)
- Encoder: 입력 데이터를 인코딩(부호화)
- Decoder: 인코딩된 데이터를 디코딩(복호화)
여기서 잠깐!
*부호화: 'A'라는 문자를 '1000001'이라는 이진수로 변환 (자연어를 컴퓨터 언어로 변환)
*복호화: '1000001' 이진수를 다시 'A'라는 문자로 변환 (컴퓨터 언어를 자연어로 변환)

출발어인 "나는 고양이로소이다"가 Encoder에 들어가면 인코딩이 되어
Decoder에 들어가게 되고 Decoder는 도착어 문장을 생성한다.
좀 더 자세히 보면,
Encoder가 인코딩한 정보에는 번역에 필요한 정보가 조밀하게 응축
Decoder는 조밀하게 응축된 이 정보를 바탕으로 도착어 문장 생성
seq2seq의 전체 그림
Encoder와 Decoder가 협력해 시계열 데이터를 다른 시계열 데이터로 변환
그리고! RNN을 사용할 수 있다!
5-1. Encoder

시계열 데이터 -> h라는 은닉 상태 벡터 변환 (고정 길이)
즉, '인코딩한다'라는 표현은 '임의 길이의 문장을 고정 길이 벡터로 변환'하는 것을 의미
참고) 여기서는 LSTM을 사용했지만 '단순한 RNN', 'GRU' 등을 사용 가능

5-2. Decoder
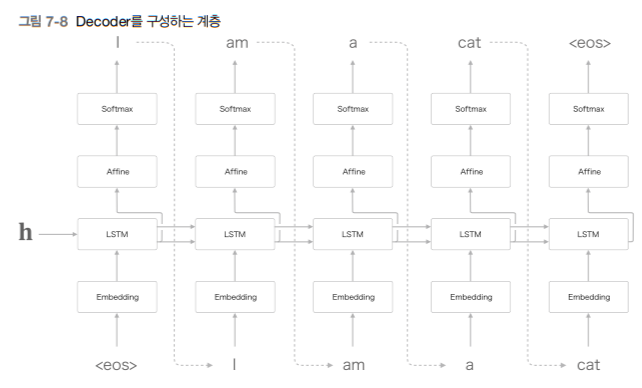
LSTM 계층이 h라는 벡터를 입력받는 것만 제외하면 이전의 신경망과 동일. (문장 생성 모델)
5-3. 전체 계층 구성
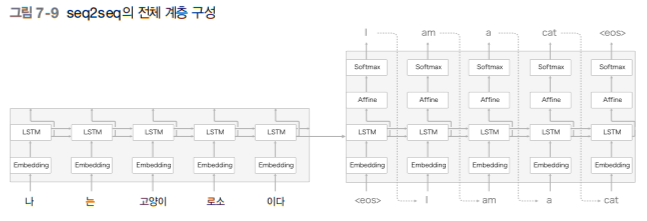
seq2seq는 Encoder의 LSTM 하나와 Decoder의 LSTM 하나로 총 2개의 LSTM으로 이루어져 있다.
중간에 은닉 벡터 h를 통해
순전파때는 인코딩된 정보가 Decoder로 넘어가고
역전파때는 기울기가 Encoder로 넘어간다.
6. 시계열 데이터 변환용 Toy Problem
*Toy Problem: 머신러닝을 평가하고자 만든 간단한 문제
과연 seq2seq 모델은 덧셈을 잘 학습해서 덧셈을 하게 될 수 있을까? (잘..안 될 것)

이전까지는 '단어' 단위로 분할했다면 이번 문제에서는 '문자'단위로 분할
예시) "57+5"가 입력되면 ['5', '7', '+', '5']라는 리스트로 처리
6-1. 가변 길이 시계열 데이터
*가변 길이 시계열 데이터: 덧셈 문장이나 그 대답의 문자 수가 문제마다 다르다.
샘플마다 데이터의 시간 방향 크기가 다르다.
해결방안?
1) 패딩: 원래의 데이터에 의미 없는 데이터를 채워 모든 데이터의 길이를 균일하게 맞추는 기법
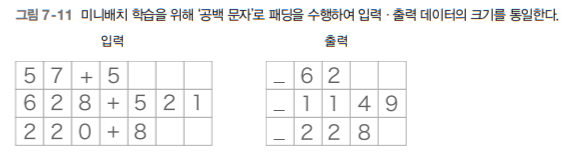
출력 앞에 '_'를 붙여 출력임을 표시하고 Decoder에서 문자열을 생성하라는 신호로 사용.
하지만 패딩 전용 처리도 추가해야 한다!
- Decoder에 입력된 패딩이라면 손실의 결과에 반영되지 않게 해야 함. (Softmax with Loss 계층에 'mask' 기능 추가)
- Encoder에 입력된 패딩이라면 LSTM계층이 이전 시각의 입력을 그대로 사용(패딩이 없었던것과 같은 효과)
6-2. 덧셈 데이텃을 이용해보자

import sys
sys.path.append('..')
from dataset import sequence
(x_train, t_train), (x_test, t_test) = \
sequence.load_data('addition.txt', seed=1984)
char_to_id, id_to_char = sequence.get_vocab()
print(x_train.shape, t_train.shape)
print(x_test.shape, t_test.shape)
# (45000, 7) (45000, 5)
# (5000, 7) (5000, 5)
print(x_train[0])
print(t_train[0])
# [ 3 0 2 0 0 11 5]
# [ 6 0 11 7 5]
print(''.join([id_to_char[c] for c in x_train[0]]))
print(''.join([id_to_char[c] for c in t_train[0]]))
# 71+118
# _1891) load_data를 통해 텍스트를 문자ID로 치환, 훈련과 테스트 데이터로 나눈다.
2) get_vocab를 통해 문자와 문자ID의 딕셔너리를 반환
3) x_train, t_train: 문자ID가 저장
4) char_to_id, id_to_char: 문자 <-> 문자ID 상호 변환 가능
결과는 71 + 118 = _189 로 잘 계산되었다.
7. Encoder 클래스

1) Embedding 계층(문자 ID를 문자 벡터로 변환)과 LSTM 계층(은닉 상태 출력)으로 이루어짐
*LSTM 계층의 위쪽 출력은 폐기(다른 계층이 없어서)
2) 은닉 상태 h를 Decoder에 보낸다.

- Time 계층을 이용해 Encoder를 구현
Encoder 클래스 code
import sys
sys.path.append('..')
from common.time_layers import *
from common.base_model import BaseModel
class Encoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=False)
self.params = self.embed.params + self.lstm.params
self.grads = self.embed.grads + self.lstm.grads
self.hs = None
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
self.hs = hs
return hs[:, -1, :]
def backward(self, dh):
dhs = np.zeros_like(self.hs)
dhs[:, -1, :] = dh
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout1) 초기화 메서드: vocab_size, wordvec_size, hidden_size
*vocab_size: 어휘수 (문장의 종류) (책에서는 0~9의 숫자와 '+', ''(공백), '_'을 합쳐 총 13가지 문자 사용)
*wordvec_size: 문자 벡터의 차원 수
*hidden_size: LSTM 계층의 은닉 상태 벡터 차원 수
2) params, grads
*params: 가중치 매개변수
*grads: 기울기
3) forward
Time Embedding 계층과 Time LSTM 계층의forward() 메서드를 호출
Time LSTM 계층의 마지막 시각의 은닉 상태만을 추출해, 그 값을 출력으로 반환
4) backward
LSTM 계층의 마지막 은닉 상태에 대한 기울기가 dh 인수로 전해짐. (Decoder가 전해주는 기울기)
np.zeros_like를 통해 원소가 모두 0인 텐서 dhs를 생성, dhs를 dh의 해당 위치에 할당.
마지막으로 Time LSTM 계층과 Time Embedding 계층의 backward() 메서드 호출
'ML DL' 카테고리의 다른 글
| [지시딥] chapter6. 배치 정규화, 드롭아웃, 하이퍼파라미터 갱신 p210~226 (0) | 2022.02.16 |
|---|---|
| [지시딥] SGD와 BGD 그리고 학습 (0) | 2022.02.16 |
| [지시딥] chapter 6 .학습 관련 기술들(p189~208) (0) | 2022.02.16 |
| [논문읽기][STARK]Learning Spatio-Temporal Transformer for Visual Tracking (0) | 2022.02.16 |
| [논문읽기][SSD]Single Shot MultiBox Detector (0) | 2022.02.16 |
- Total
- Today
- Yesterday
- 인공지능교육
- 멋쟁이사자처럼
- AIFFEL후기
- 모두의 연구소
- ros
- AIFFEL교육
- 양정연SLAM
- 광주인공지능사관학교
- Python
- 인공지능
- 실내자율주행
- 광주
- SLAM공부
- 배달로봇
- 대전 인공지능
- 도전
- 아이펠
- 자율주행로봇
- SLAM강의
- 해커톤
- 모두의연구소
- 자율주행기술
- Slam
- 서빙로봇
- 인공지능 교육
- 광주AI
- 멘탈관리
- AIFFEL
- AIFFEL인공지능과정
- IT
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |